在前一篇文章中,介绍了 UE 的反射的基础概念,这篇文章开始研究 UE 的反射机制的具体实现。
在介绍 UE 的代码之前,需要先要介绍一些 C++ 特性,虽然 UE 的反射实现是大量依赖 UHT 的代码生成的,但是也需要 C++ 的语法特性支持,只有把这些特性还有它们背后的含义了解清楚,才能够更好地理解 UE 的反射机制。
本篇文章中介绍的 C++ 的特性和标准描述均基于ISO/IEC 14882:2014,也就是 C++14 标准。
要介绍的实现反射依赖的 C++ 特性,就是把 C++ 中类型的信息通过什么样的方式存储下来供运行时访问。
class/struct
对于 C++ 的类而言,需要着重关注的是内存布局,因为类实例本质就是一块内存,而如何解释这块内存,需要通过类的类型信息来确定。
在 C++ 中 struct 和class来定义类,只有默认的访问控制权限有差别,在 UE 中则不同,USTRUCT 和 UCLASS 则进行了严格的区分,USTRUCT 不能具有反射函数。
数据成员
因为兼容 C 的以及语言特性的实现,C++ 还有 POD 的概念。而介绍 POD 则又先要介绍 C++ 标准中的standard-layout class([ISO/IEC 14882:2014 9.1.7]):
A standard-layout class is a class that:
- has no non-static data members of type non-standard-layout class (or array of such types) or reference,
- has no virtual functions (10.3) and no virtual base classes (10.1),
- has the same access control (Clause 11) for all non-static data members,
- has no non-standard-layout base classes,
- either has no non-static data members in the most derived class and at most one base class with
non-static data members, or has no base classes with non-static data members, and - has no base classes of the same type as the first non-static data member.
因为 C++ 在实现特性的时候会往原始的内存布局中插入或调整成员顺序,所以 C++ 标准中对 standard-layout class 做了上述限定。
可以把 POD 理解为只有数据的类,并且数据成员的排列顺序是固定的(不能包含多个不同的访问控制权限,因为编译器 有可能 会混排,标准中没有做保证),除了内存对齐外,不会被插入额外的内存。
在我之前的一篇文章:结构体成员内存对齐问题 里介绍了内存对齐。因为内存对其的存在,类内数据成员并不是严格的一个挨着一个存放的,内存布局中会有一些空隙,这样会有两个问题:
- 数据成员在类内的偏移地址是依赖于内存对齐的
- 不同的声明顺序会导致类布局的变化(编译器也有可能对不同的访问控制权限进行重排)
为了获取数据成员在类内的偏移值,而不用考虑上面一堆的东西,C++ 引入了一个特性:Pointers to members,翻译过来就叫做 指向成员的指针 ,这部分内容的详细描述在ISO/IEC 14882:2014 §8.3.3 中。
在我之前的一篇文章中,也对指向成员的指针做过比较详细的介绍:C++ 中指向类成员的指针并非指针。
指向类成员的指针,重点就是来获取数据成员、函数相对于类型的描述信息,比如数据成员在类布局中的偏移,成员函数的 this 偏移值、成员函数的原始函数指针,得到了这些信息才能通过类实例访问到具体的成员。
如以下类:
1 | class ClassExample |
来获取它三个成员的内部偏移值:
1 | bool ClassExample::*bBoolean = &ClassExample::bBoolean; |
通过 LLVM-IR 翻译之后可以更直观地看到:
1 | store i64 0, i64* %1, align 8 |
如果把类定义中的 func 改成 virtual 呢?
1 | store i64 8, i64* %1, align 8 |
可以看到内存布局的变化,这是因为类中有了虚函数,往类布局中插入了虚表指针,占用了 8 个字节。
小结一下:通过成员函数指针等特性,可以在编译时就确定数据成员在类布局中的偏移,通过 该偏移 + 数据成员的类型大小(sizeof),就可以正确地访问到指定的成员所在的内存了。
但是,C++ 中也有一个限制,就是不能对位域取地址:
The address-of operator & shall not be applied to a bit-field, so there are no pointers to bit-fields.
位域在 UE 中被广泛地应用于 bool 值,C++ 中对该用法有保证:
A bool value can successfully be stored in a bit-field of any nonzero size.
并且,位域的分配和对齐是实现定义的:
[ISO/IEC 14882:2014 9.6 Bit-fields]Allocation of bit-fields within a class object is implementation-defined. Alignment of bit-fields is implementation-defined.
因为不能对位域进行取地址,所以在反射实现中需要对 uint8 bEnable:1; 做一些特殊处理,要能得到位域中的位。
以 FBoolProperty 中获取 bool 值的实现为例:
1 | FORCEINLINE bool GetPropertyValue(void const* A) const |
同时兼容了 NativeBool 和bit-field。
对于 uint8 bit_field:1; 和bool native_bool;两种反射信息的生成,以反射信息中的 UE4CodeGen_Private::EPropertyGenFlags::NativeBool 来区别,具有该 flag 的是bool native_bool;。
成员函数
UE 的反射函数都是成员函数,并且需要继承自 UObject。
UE 中成员函数实现反射,并没有依赖 C++ 的指向成员函数的指针,它完全依赖 UHT 生成了一个统一原型的 Thunk 函数,在 Thunk 函数中调用真正执行的函数(包括从栈上取数据等操作)。
并且会为反射的函数生成用于传递给 ProcessEvent 函数的参数结构,以及每个参数、返回值生成属性的反射信息(它们的内存偏移都是相对于 UHT 生成的参数结构的)。
如以下函数:
1 | UFUNCTION() |
UHT 生成的 Thunk 函数为:
1 | DEFINE_FUNCTION(URefObject::execfunc) |
用这种方式,统一了所有的反射函数的调用原型为:
1 | void execfunc(UObject* Context, FFrame& Stack, RESULT_DECL) |
每个反射的函数都可以从这个原型中获取自己的参数,从而执行真正的函数调用行为(或者执行蓝图字节码)。
enum
枚举值不是整数,但是它可以被提升为整数类型。
[ISO/IEC 14882:2014]Therefore, enumerations (7.2) are not integral; however, enumerations can be promoted to integral types as specified in 4.5.
在 UE 的 UEnum 中枚举值使用 int64 来存储,所以,只要我们知道了枚举的名字,还有它名字所对应的整数值,就可以在名字和整数值以及枚举之间进行相互转换了。
UHT 会给添加了 UENUM 的枚举生成这些信息,并在运行时构造出 UEnum 实例存储这些信息。
UE 中的 Enum 写法:
1 | UENUM() |
UHT 生成的部分反射代码:
1 | static const UE4CodeGen_Private::FEnumeratorParam Enumerators[] = { |
基于反射 UEnum 进行字符串、枚举值的转换:
1 | template<typename ENUM_TYPE> |
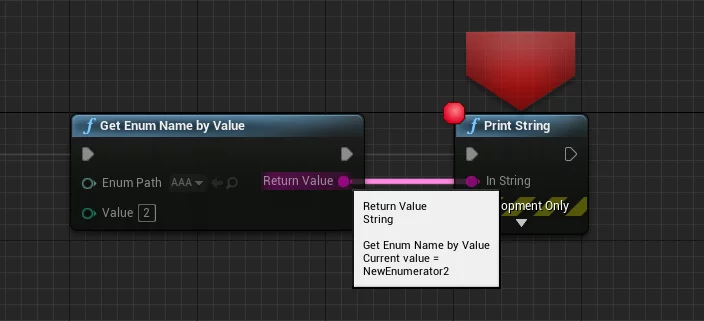
而且也可以访问蓝图中的 Enum:
1 | FString UFlibAppHelper::GetEnumNameByValue(TSoftObjectPtr<UUserDefinedEnum> EnumPath, int32 value) |
scoped enum
随便写一点点番外,C++ 的 scoped enum。
C++11 引入了 scoped enum:
1 | enum class EClassEnum{ |
为什么要引入这么语法呢?因为 C++11 之前的 enum,其枚举值得定义是位于整个所属名字空间的。C++ 标准中的描述:
[ISO/IEC 14882:2014 §7.2]The enumeration type declared with an enum-key of only enum is an unscoped enumeration, and its enumerators are unscoped enumerators.
下面代码就会出现重定义错误:
1 | enum ENormalEnum{ |
所以在一般写代码时会加上 namespace 来人为地区分枚举的名字空间:
1 | namespace ENamespaceEnum |
因为上面 Type 的枚举值是位于当前 namespace 的,所以就可以以下面这种形式来使用:
1 | ENamespaceEnum::A; |
这其实是一种弱类型枚举,枚举本身并不是一个类型。所以 C++11 引入了 Scoped Enum,可以理解为强类型枚举:
1 | enum class EScopedEnum{ |
使用它可以具有与上面 namespace 形式一样的效果。
Scoped Enumeration 的值也是可以显式转换为数值类型的:
[ISO/IEC 14882:2014 §5.2.9]A value of a scoped enumeration type (7.2) can be explicitly converted to an integral type.
而且,如果 scoped enum 的基础类型没有被显式指定的话,它的默认基础类型是 int:
[ISO/IEC 14882:2014 §7.2]Each enumeration also has an underlying type. The underlying type can be explicitly specified using enum-base; if not explicitly specified, the underlying type of a scoped enumeration type is int.
在 LLVM 中,对 Scoped enum 的处理是在编译器前端做的,下列代码生成的 IR 代码:
1 | enum ENormalEnum{ |
main 函数的 LLVM-IR:
1 | ; Function Attrs: uwtable |
在生成 IR 时就没有符号信息,只剩常量了。
static 的构造时机
UE 里的反射技术也依赖了 C++ 的 static 构造时机,如gen.cpp 中的:
1 | static FCompiledInDefer Z_CompiledInDefer_UClass_URefObject(Z_Construct_UClass_URefObject, &URefObject::StaticClass, TEXT("/Script/RefExample"), TEXT("URefObject"), false, nullptr, nullptr, nullptr); |
C++ 标准中对 static 的构造时机介绍:
It is implementation-defined whether the dynamic initialization of a non-local variable with static storage duration is done before the first statement of main.
虽然标准里写的 implementation-defined 行为,但是几乎用到的编译器都是这么干的。